| Използвайки Economy.bg, Вие се съгласявате с "Политика за Cookies/Бисквитки" , необходими за пълната функционалност на услугата. [X] |
|
|
|
998 прочитания
Как машинното обучение стои зад алгоритъма на Facebook?
Сложни процеси определят класирането и подбора на съдържание
 Разработката на персонализирана система за класиране и разпределение на съдържание за повече от 2 млрд. потребители с различни интереси е сложна задача. Акос Лада, мениджър в отдела за науки за данните във Facebook, Мейхонг Уанф, директор в инженерния отдел на Facebook, и Так Ян, директор в отдела за продукти на Facebook, разкриват как социалната мрежа превъзмогва предизвикателствата за класирането на съдържание на стената с помощта на машинно обучение и изкуствен интелект. Без умни алгоритми, които да анализират съдържанието, стената на потребителите може да бъде запълнена със съдържание, което не отговаря на интересите им. Системата за класиране съществува именно с тази цел да разпределя съдържанието по начин, подсигуряващ доставката му до тази аудитория, която има най-голям интерес в областта. С помощта на машинно обучение инженерите във Facebook са създали система, която предвижда какво би харесал всеки потребител. За целта се използват модели за обучение с множество източници, невронни мрежи, системи за вграждане и технологии за офлайн обучение. 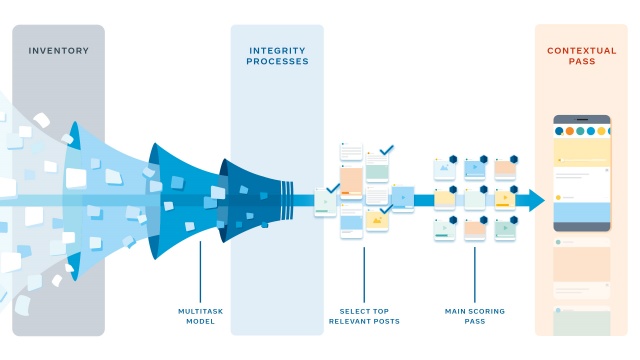 Изграждането на алгоритъм за класиране Понеже Хуан е свързан или следва продуцентите на това съдържание се предполага, че всички тези публикации биха представлявали интерес за него. За да може Facebook да покаже някои от тези публикации, първо, преди да продължи с всичко останало, социалната мрежа трябва да предвиди какво Хуан би харесал най-много. Изразено с математически термини, Facebook трябва да дефинира обективна функция за Хуан и да извърши оптимизация на една единствена цел. Например видеото на Санави от сутрешната ѝ разходка би било прието като интересно за Хуан, ако той е харесал други подобни материали. Данните за една публикация, като времето на публикуване и хората, които са отбелязани в нея, Facebook отбелязва с Xit. Те се съпоставят със зрителя j във време t и предвиждат Yijt, което отбелязва дали Хуан би харесал публикацията. Математически за всяка публикация i социалната мрежа може да изчисли, че Yijt = f(xijt1;xijt2; … xijtC). В тази формула C се използва за отбелязването на характеристика, като вида публикация или връзката между публикуващия и консумиращия съдържанието. Например дали те са отбелязали, че са членове на същото семейство. Функцията е отбелязана с f, а скобите обединяват всички параметри в една крайна стойност. Например ако Хуан обикновено харесва или споделя съдържанието на Санави и новото ѝ видео е публикувано скоро, то шансовете Хуан да хареса новия клип са големи. От друга страна, Хуан може да е взаимодействал повече с видео, отколкото със снимков материал в миналото, което означава, че снимката на кучето на Уей има по-малки шансове да бъде харесана. В тези случаи алгоритъмът за класиране ще определи видеото на Санави като съдържание с по-голям приоритет пред снимката на Уей, понеже предвижда по-голяма вероятност Хуан да хареса това съдържание. Алгоритъмът взема предвид и други фактори, тъй като харесването на публикация не е единственото действие, което Хуан може да предприеме. Той може да сподели статии, които намира за интересни, да гледа видео с любими игри или да коментира върху публикации на приятели. Процесът става по-сложен, когато социалната мрежа трябва да предвиди повече неща и да оптимизира съдържанието си за различни цели. Стойностите Yijtk може да са различни. Те може да са харесвания, коментари и споделяния. Може да са с различна стойност, която Facebook отбелязва с K. Тя трябва да бъде обединена в една единица Vijt. Във Facebook има хиляди сигнали, които трябва да бъдат идентифицирани, за да може социалната мрежа да предвиди какво би било интересно на потребителя. Това усложнява нещата и съответно прави алгоритъма сложен. Facebook трябва да прецени кое съдържание създава дългосрочна стойност за Хуан. За целта социалната мрежа трябва да избере данни, които са сходни с това, което потребителите са посочили като важно за тях. Именно затова Facebook анкетира дали показаните публикациите са били от интерес и дали са заслужили времето на потребителите. По този начин Yijtk представя стойност за това кое потребителите намират за полезно. Различни модели за предвиждане предлагат различни стойности за Хуан. Например един модел ще прецени дали потребителят ще хареса, коментира или сподели публикацията на Уей, друг - ще прецени това Санави. Трети за материала от Facebook страницата и четвърти за материала от Facebook групата. Всеки един от тези модели ще се опита да оцени съдържанието според предпочитанията на Хуан. Понякога моделите може да нямат разбирателство. Например Хуан може да хареса повече видеото на Санави от публикацията от страницата във Facebook, но може да е по-склонен да сподели статията, отколкото видеото. Затова Facebook взема предвид какви предпочитания потребителите споделят със социалната мрежа. Предвиждането на идеалната функция за класиране в цялостна система, която може да бъде приложена масово За целта компанията споделя, че архитектурата им използва слой Web/PHP. Той се допитва до алгоритъма, съставящ стената за всеки потребител. Целта на този алгоритъм е да събере цялата информация за една публикация и да анализира всички параметри, като колко души са харесали подобни публикации в миналото. По този начин Facebook предвижда стойността на публикацията Yijt за потребителя, както и финалния резултат за класирането Vijt, като събере на едно място всички прогнози. 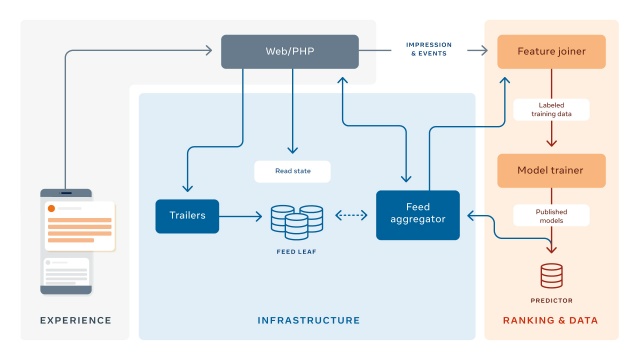 Как работи алгоритъмът за компилация? Впоследствие програмата ще оцени Xit за Хуан за всяка прогноза (Yijt). Щом алгоритъмът има целия инвентар от публикации и прогнози, той оценява всяко съобщение с помощта на невронни мрежи, които могат да изпълняват множество задачи едновременно. Съществуват множество характеристики (xijtc), които Facebook може да използва, за да предвиди Yijt, включително вида публикация, други прогнози, генерирани от модели за машинно обучение, и предпочитанията на потребителя. За да извърши калкулациите за повече от хиляда публикации за всеки от милиардите си потребители, Facebook прави изчисленията едновременно на няколко отделни машини, наречени „предсказвачи“. Последната стъпка е изчисляването на един финален резултат на база на данните от всички прогнози: Vijt. За целта Facebook прави това на няколко етапа, за да намали консумацията на компютърни ресурси и също така да приложи определени правила за разнообразяване на съдържанието. Това предотвратява показването на няколко публикации от един и същи автор или няколко видео материала един след друг. В първия преглед се използва лек модел, който подбира около 500 от най-значимите публикации за потребителя. Това позволява анализа на по-малко съдържание с висок резултат в следващите стъпки, където Facebook използва по-мощни невронни мрежи. Следващият етап е основният процес за оценка. При него всяка история се оценява независимо и всички 500 публикации се подреждат според резултата. По-голямата част от персонализирането на съдържанието се случва тук. Facebook споделя, че целта им е да оптимизират как комбинират Yijtk във Vijt. За някои потребители публикации, които могат да привлекат голям брой харесвания, може да са с приоритет пред такива, които биха привлекли повече коментари, тъй като този определен потребител харесва повече съдържание, вместо да коментира. С цел опростяване на процеса Facebook оценява прогнозите си в линеен ред: Vijt = wijt1Yijt1 + wijt2Yijt2 + … + wijtkYijtk. Тази линейна формула има преимущество: всяко действие, което един човек не изпълнява често (като прогноза, която е близка до 0) автоматично получава минимален резултат, тъй като Yijtk за това действие е малка стойност. Персонализацията продължава на базата на други наблюдения. Например публикации от потребители с по-задълбочена връзка получават по-висок резултат, стига методът да прави изчисленията постепенно и да има контрол за възможни объркващи променливи. Последният етап оценява контекста, като вида на съдържанието и правила за избягването на съдържание от един и същи тип да се показват едновременно. Щом приключат процесите, описани по-горе, Facebook може да генерира стената за Хуан, която съдържа оценени публикации. Всяка публикация се появява според оценката си. Тези с по-висока оценка се появяват първи.
|
Искам да се абонирам за седмичния бюлетин на Economy.bg:
* Въведеният имейл се използва само за целите на абонамента, имате възможност да прекратите абонамента по всяко време.
|









|
|
|
Copyright © 2024 economy.bg. Издание
на jobs.bg
|